第 18 章 可解释性人工智能
我们已经介绍了众多的机器学习模型以及不同的研究领域以及各种有趣的应用场景,当一个机器学习算法真正在工业界落地时,会有一个问题:机器学习模型往往是一个黑盒子,无法解释这个黑盒子中是如何通过输入得到输出的。但模型的安全性在行业落地时十分重要,因此我们势必要对于人工智能算法、模型的解释性的进行研究。
18.1 可解释性人工智能的重要性
我们首先介绍可解释性人工智能(eXplainable Artificial Intelligence,XAI)的概念,以及可解释性人工智能的重要性。目前为止,我们已经训练了很多的模型。比如图像识别模型,给它一张图片,模型会给你图像的类别。但我们并不满足于此,接下来我们要机器给我们它得到答案的理由,这就是可解释性人工智能,学者们普遍将可解释性人工智能称为XAI。首先开始介绍技术之前,我们需要讲一下为什么可解释性人工智能是一个重要的研究领域。其实本质上的原因是就算机器可以得到正确的答案,也不代表它一定非常“聪明”。举一个例子,过去有一匹神马它很聪明,它可以做数学问题。比如问它
以上是一个故事,当然在很多的真实应用中,可解释性的机器学习,或者说可解释性的模型往往是必须的。举例来说,银行可能会用机器学习的模型来判断要不要贷款给某一个客户,但是根据法律的规定银行作用机器学习模型来做自动的判断它必须要给出一个理由。所以这个时候,我们不是只训练机器学习模型就好,我们还需要机器学习的模型是具有解释力的。机器学习未来也会被用在医疗诊断上,但医疗诊断是人命关天的事情,如果机器学习的模型只是一个黑箱,不会给出诊断的理由的话,那我们又要怎么相信它做出的是正确的判断呢。现在也有人想把机器学习的模型用在法律上,比如说帮助法官判案,比如一个犯人能不能够被假释,但是我们怎么知道机器学习的模型它是公正的呢,它是不是有种族歧视的问题呢。所以我们希望机器学习的模型不只得到答案它还要给我们得到答案的理由。再更进一步,自动驾驶汽车未来可能会满街跑,但是当自动驾驶汽车突然急刹的时候导致车上的乘客受伤,这个自动驾驶系统有没有问题呢?这也许取决于它急刹的理由,如果它是看到有一个老人在过马路所以急刹,那也许它是对的,但是假设它只是无缘无故就突然发狂要急刹,那这个模型就有问题了。所以对它的种种行为、种种决策,我们希望知道决策背后的理由。更进一步,也许机器学习的模型如果具有解释力,未来我们可以凭借着解释的结果再去修正模型。
我们期待也许未来当我们知道深度学习模型犯错的时候,它是错在什么样的地方,它为什么犯错,也许我们可以有更好的、更有效率的方法来提升模型。当然这个是未来的目标,离用可解释性的机器学习做到上述模型的想法还有很长的一段距离。但是已经有一些方法可以让模型变得比较容易解释,也许未来我们可以把这些方法应用在深度学习的模型上,让深度学习的模型也变得比较容易解释。
有人可能会想说我们之所以这么关注可解释性的机器学习的议题,也许是因为深度的网络本身就是一个黑箱。我们能不能够用其它的机器学习的模型呢?如果不要用深度学习的模型,而改采用其他比较容易解释的模型会不会就不需要研究可解释性机器学习了呢。举例来说,假设我们都采用线性模型,它的解释的能力是比较强的,我们可以轻易地知道根据一个线性模型里面的每一个特征的权重,知道线性的模型在做什么事。所以训练完一个线性模型后,我们可以轻易地知道它是怎么得到它的结果的。但是线性模型的问题是它没有非常地强大,它的表达能力是比较弱的。线性模型有很巨大地限制,所以我们才很快地进入了深度的模型。深度模型它的坏处就是它不容易被解释,深度网络它就是一个黑盒子,黑盒子里面发生了什么事情,我们很难知道。虽然它比线性的模型更好,但是它的解释的能力是远比线性的模型要差的。所以讲到这里,很多人就会得到一个结论,我们就不应该用这种深度的模型,我们不该用这些比较强大的模型,因为它们是黑盒子。但是这样的想法其实就是削足适履,我们因为一个模型它非常地强大,但是不容易被解释就扬弃它吗?我们不是应该是想办法让它具有可以解释的能力吗?所以我们的目标就是要让深度的模型也具有解释的能力,而不是说我们就不要用深度的模型了。当然对于机器学习的可解释性还有很多的讨论,但是其重要性是不言而喻的。
18.2 决策树模型的可解释性
我们首先介绍一下一个比较简单的机器学习模型,其在设计之初就已经有了比较好的可解释性,这个模型就是决策树模型。决策树相较于线性的模型,它是更强大的模型。而决策树的另外一个好处,相较于深度学习它具有良好的可解释性。比如从决策树的结构,我们就可以知道模型是凭借着什么样的规则来做出最终的判断。所以我们希望从决策树模型进行可解释性的研究,再扩展到其他机器学习模型,甚至深度模型。
我们首先简单介绍一下决策树,它有很多的节点,那每一个节点都会问一个问题,让你决定向左还是向右。最终当你走到节点的末尾,即叶子节点的时候,就可以做出最终的决定。因为在每一个节点都有一个问题,我们看那些问题以及答案就可以知道现在整个模型凭借着什么样的特征如何做出最终的决断。所以从这个角度看来,决策树它既强大又有良好的可解释性。那我们是不是就可以用决策树来解决所有的问题呢?其实不是的,它是一个树状的结构,那我们可以想像一下,如果特征非常地多,得到决策树就会非常地复杂,就很难去解释它了。因为其节点太多而且很难分析得到整个模型的规则。所以复杂的决策树也有可能是一个黑盒子,它也有可能是一个非常地复杂的模型,所以我们也不能够一味地去使用决策树。
另外一方面,我们是怎么实际使用决策树这个技术的呢?很多同学都会说,这个打 Kaggle比赛的时候,深度学习不是最好用的,决策树才是最好用的,决策树才是 Kaggle 比赛的常胜将军。但是其实当你在使用决策树的时候,并不是只用一棵决策树,你真正用的技术叫做随机森林。真正用的技术其实是好多棵决策树共同决定的结果。一棵决策树可以凭借着每一个节点的问题和答案知道它是怎么做出最终的判断的,但当你有一片森林的时候,你就很难知道说这一片森林是怎么做出最终的判断的。所以决策树也不是最终的答案,并不是有决策树,我们就解决了可解释性机器学习的问题。
18.3 可解释性机器学习的目标
为了解释比如决策树、随机森林的意义,我们首先应该定义可解释性的目标是什么。或者说什么才是最好的可解释性的结果呢?很多人对于可解释性机器学习会有一个误解,觉得一个好的可解释性就是要告诉我们整个模型在做什么事。我们要了解模型的一切,我们要知道它到底是怎么做出一个决断的。但是这件事情真的是有必要的吗?虽然我们说机器学习模型,深度网络是一个黑盒子,不能相信它,但世界上有很多黑盒子,比如人脑也是黑盒子。我们其实也并不完全知道,人脑的运作原理,但是我们可以相信,另外一个人做出的决断。那为什么深度网络是一个黑盒子,我们就没有办法相信其做出的决断呢?我们可以相信人脑做出的决断,但是我们不可以相信深度网络做出的决断,这是为什么呢?
以下是一个和机器学习完全无关的心理学实验,这个实验是 1970 年一个哈佛大学教授做的。这个实验是这样,在哈佛大学图书馆的打印机经常会有很多人都排队要印东西,这个时候如果有一个人跟他前面的人说拜托请让我先印 5 页,这个时候你觉得这个人会答应吗?据统计有
所以会不会可解释性机器学习也是同样的道理。在可解释性机器学习中,好的解释就是人能接受的解释,人就是需要一个理由让我们觉得高兴。因为很多人听到,深度网络是一个黑盒子他就不爽,但是你告诉他说这个是可以被解释的,给他一个理由,他就高兴了。所以或许好的解释就是让人高兴的解释。其实这个想法,这个技术的进展是蛮接近的。
18.4 可解释性机器学习中的局部解释
可解释性机器学习可以被分成两大类,第一大类叫做局部的解释,第二大类叫做全局的解释,如图 18.1 所示。局部的解释是,比如有一个图像分类器,输入一张图片,它会判断出是一只猫,机器要回答问题是为什么它觉得这张图片是一只猫。根据某一张图片来回答问题,这个叫做局部的解释。还有另外一类,称为全局解释。其指还没有给分类器任何图片,而直接问对一个分类器而言,什么样的图片叫做猫。我们并不是针对任何一张特定的图片来进行分析,我们是想要知道有一个模型它里面有一些参数的时候,对这些参数而言什么样的东西叫作一只猫。
接下来我们先来看第一大类,第一大类是为什么你觉得一张图片是一只猫。再具体一点些,给机器一张图片,它知道图片是一只猫的时候,到底是这个图片里面的什么东西让模型觉得它是一只猫。或者讲的更宽泛一点,假设模型的输入叫做
如何知道一个部分的重要性呢?基本的原则是我们把所有的部分都拿出来,把每一个部分做改造或者是删除。如果我们改造或删除某一个部分以后,网络的输出有了巨大的变化,就知道这个部分没它不行,它很重要。我们再使用图像举例,想要知道一个图像里每一个区域的重要性的时候,就将这个图片输入到网络里。接下来在这个图片里面不同的位置放上灰色的方块,当这个方块放在不同的地方的时候,网络会输出不同的结果。比如一只狗的图片,当我们把灰色的方块移动到狗的脸上的时候,我们网络就不觉得它看到一只狗;但如果把灰色的方块放在狗的四周,这个时候机器就觉得它看到的仍然是狗。所以模型就知道它不是看到球,觉得它看到狗,也不是看到地板、墙壁,才觉得看到的是狗,而是真的看到这个狗的面部。所以这个是最简单的,知道每一个部分的重要性的方法。
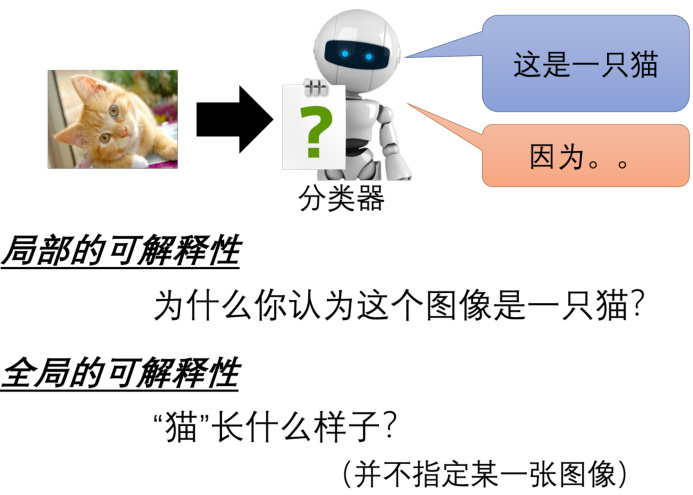
图 18.1 可解释性机器学习的两大类别
还有一个更进阶的方法,即计算梯度,如图 18.2 所示。具体来讲,假设我们有一张图片,我们把它写为
再举一个真实的案例,有一个基准语料库叫做 PASCAL VOC 2007,里面有各式各样的物体,有人、狗、猫、马、飞机等等。机器要学习做图像分类,当它看到图中这张图片它知道是马,如图 18.3 所示。如果我们看显著图的话,就会发现机器觉得这张图片是马的原因,是因为图片的左下角有一串英文,这串英文是来自于一个网站,这个网站里面有很多马的图片,左下角都有一样的英文,所以机器看到左下角这一行英文就知道是马,它根本不需要学习马是长什么样子。所以在这个真实的应用中,在基准语料库中,类似的状况也是会出现的。所以这告诉我们,可解释性 AI 是一个很重要的技术,否则我们不知道机器是怎么判断的,我们就不知道它是不是在作弊,或者是不是有什么问题。
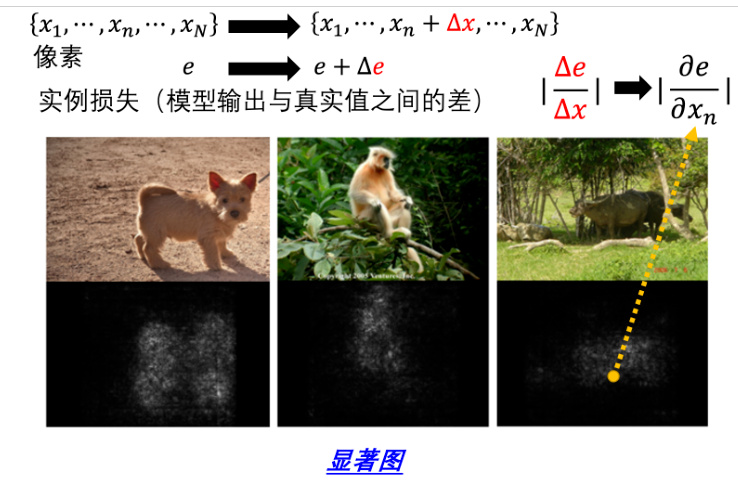
图 18.2 计算梯度进行重要性评判

图 18.3 模型误判的显著图解释
其实可以把可解释性机器学习的显著图画得更好,可以使用一种叫做 SmoothGrad 的方法,如图 18.4 所示。这张图片是羚羊,所以我们希望机器会把它主要的精力集中在瞪羚身上。那如果我们用刚才我们讲的方法直接画显著图的话,得到的结果可能是中间图的样子。其确实在羚羊附近有比较多亮的点,但是在其他地方也有一些噪声让人看起来有点不舒服,所以就有了 SmoothGrad 这个方法。SmoothGrad 会让你的这个显著图,上面的噪声比较少,在这个例子中就是多数的亮点都集中在羚羊身上。那 SmoothGrad 这个方法是怎么做呢?其实就是在图片上面加上各种不同的噪音,加不同的噪声就是不同的图片了。接着在每一张图片上面都去计算显著图,所以有加 100 种噪声,就有 100 张显著图,平均起来就得到 SmoothGrad的结果。
当然梯度并不是万能的,梯度并不完全能够反映一个部分的重要性,举一个例子以供参考,如图 18.5 所示。横轴代表的是大象鼻子的长度,纵轴代表这个生物是大象的可能性。我们都知道大象的特征是长鼻子,所以鼻子越长,这个生物是大象的可能性就越大。但是当鼻子长到一定程度以后,再长鼻子也不会让这个生物变得更像大象了。所以生物鼻子的长度跟它是大象的可能性的关系,也许一开始在长度比较短的时候随着长度越来越长,这个生物是大象的可能性越来越大。但是当鼻子的长度长到一个程度以后,就算是更长,也不会变得更像大象。这个时候如果计算鼻子长度对是大象可能性的偏导数的话,在这个地方得到的偏导数可能会趋近于 0。所以如果仅仅看梯度,仅仅看显著图,可能会得到一个结论是鼻子的长度对是不是大象这件事情是不重要的,鼻子的长度不是判断是否为大象的一个指标,因为鼻子的长度的变化,对是大象的可能性的变化是趋近于 0 的。但是事实上,我们知道鼻子的长度是一个很重要的指标,鼻子越长,这个生物是大象的可能性就越大。所以仅仅看梯度和偏导数的结果,可能没有办法完全告诉我们一个部分的重要性。所以有其他的方法被提出,比如积分梯度(integrated gradients)等等。

图 18.4 显著图的 SmoothGrad 方法
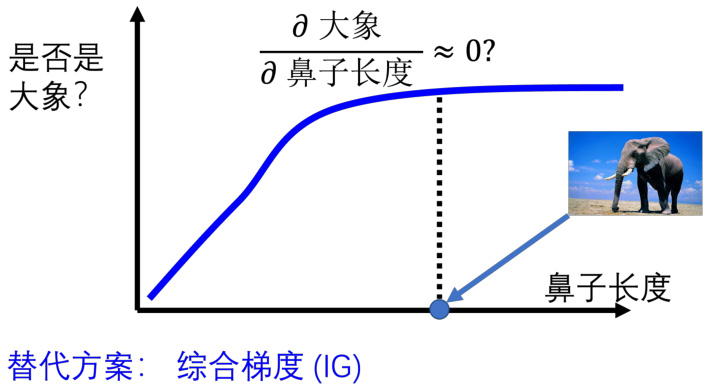
图 18.5 梯度饱和问题
刚才我们是看网络输入的哪些部分是比较重要的,那接下来我们要问的下一个问题是当我们给网络一个输入的时候,它到底是如何去处理这个输入的,并得到最终的答案的。这里也有不同的方法,第一个方法最直觉的,就是人眼去看,看看网络到底是怎么处理这个输入的。我们举一个语音的例子,如图 18.6 所示。这个网络的功能是输入一小段声音,输出这个声音是属于哪一个韵母,属于哪一个音标等等。假设该网络第一层有 100 个神经元,第二层也有100 个神经元。那第一层和第二层的输出就可以看作是 100 维的向量。通过这些分析这些向量,也许我们就可以知道一个网络里面发生了什么事。但是 100 维的向量不容易分析,所以我们可以把 100 维的向量把它降到二维,比如使用 PCA 或者
再举一个语音的例子,那这个例子来自于一篇 Hinton 的文章。首先我们把模型的输入,就是声音特征,也就是 MFCC 拿出来把它降到二维,画在二维平面上,如图 18.7 所示。这个图上每一个点代表一小段声音信号,每一个颜色代表了某一个讲话的人。其实我们输入给网络的数据有很多句子是重复的,比如 A、B、C 这三个人都说了 How are you 这句话,很多人说了一样的句子。但从声音特征上,就算是不同的人念同样的句子,我们从声音特征上并不能分别出来不同的人。所以有的人就会觉得语音识别太难了,因为不同的人说同样的话,声音特征都是一样的。但是当我们把网络拿出来可视化时候,结果就不一样了。右边的图是第 8 个隐藏层的输出,我们会发现每一条代表同样内容的某一个句子,所以不同人说同样的内容在 MFCC 上看不出来,但是它通过了 8 层的网络之后,机器知道说这些话是同样的内容了,所以最后模型就可以得到精确的分类结果。
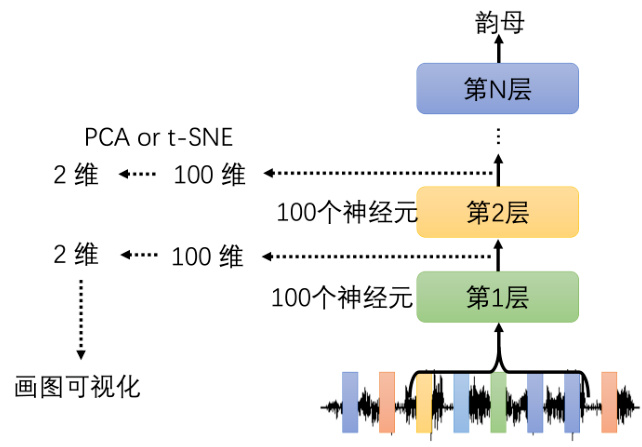
图 18.6 网络处理输入的方法一
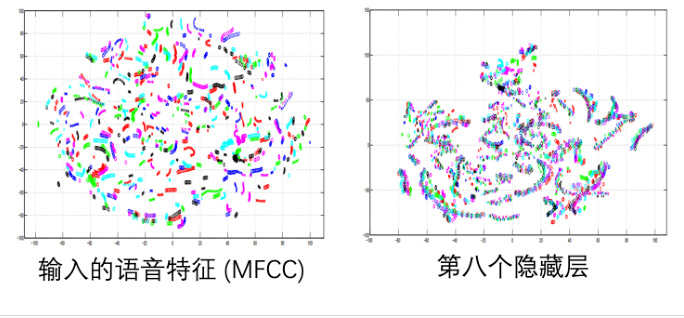
图 18.7 语音中的网络特征
除了用人眼观察可视化以外,还有另外一个技术叫做探针(probing)。简单来说,就是用探针去插入这个网络,看看会发生什么事。举例来说,如图 18.8 所示。假设我们想要知道BERT 的某一层到底学到了什么东西,除了用肉眼观察以外,你还可以训练一个探针,其实就是分类器。这个分类器是要根据一个特征向量决定现在这个词汇的词性,我们需要将 BERT的词嵌入输入到 POS 的分类器里面,这样就训练一个 POS 的分类器。这个分类器试图根据这些嵌入,决定它们分别来自于哪一个词性的词汇,如果这个 POS 分类器的正确率高,就代表说这些嵌入中有很多词性的信息;如果它正确率低,就代表这些嵌入中没有词性的信息。这样我们就可以知道 BERT 的某一层到底学到了什么东西,这个方法就叫做探针。
另一个角度,如果学习一个命名实体识别(Named Entity Recognition,NER)的分类器,这个分类器的输入是 BERT 的嵌入,输出是这个词汇是不是一个命名实体,属于人名还是地名,还是任何专有名词等等。我们透过这个 NER 分类器的正确率就可以知道这些特征里面,有没有名字、地址和人名的信息等等。但是使用这个技术的时候,我们需要小心使用的分类器的强度。假设分类器的正确率很低,真的一定保证它的输入的这些特征,即 BERT 的嵌入没有我们要分类的信息吗?不一定的,因为有可能就是分类器训练的太差了,比如学习率没有调整好等等。所以用探针模型的时候不要太快下结论,有时候我们得到一些结论只是因为分类器没有训练好。当然也有可能训练得太好导致分类器的正确率没有办法当做评断的依据。
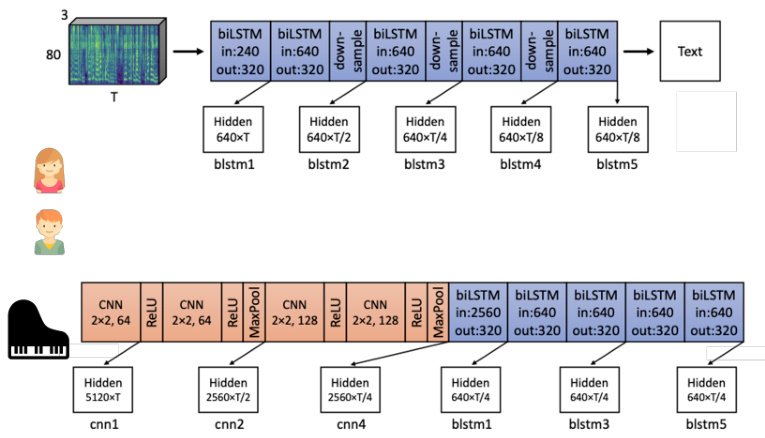
图 18.8 探针方法的 BERT 实例化
其实探针也不一定要是分类器,这边再举一个语音领域中语音合成的例子,如图 18.9 所示。训练一个语音合成的模型,一般是先输入一段文字产生对应的声音信号,这个声音信号是由一段一段的声音片段组成的,每一个声音片段都是由一段一段的音素组成的,我们这里输入“你好”。对于语音合成的模型不是输入一段文字,而是将网络输出的嵌入作为输入,再去输出一段声音信号。首先训练了一个音素的分类器,如图 18.9 右侧所示,我们把某一个层的输出输入到 TTS 的模型里面来训练这个 TTS 模型。我们训练的目标是希望 TTS 模型可以去复现网络的输入,即原是的声音信号。有人可能会问,我们训练这个 TTS 产生原来的声音信号,那有什么意义呢?这个模型的输出和输入一模一样,有什么意义呢?这里有趣的是,假设这个网络做的事情就是把讲述者的信息去掉,那对于这个 TTS 模型而言,这边第 2 层的输出没有任何讲述者的信息。那它无论怎么努力都无法还原讲述者的特征。比如,虽然内容说的是“你好”,是一个男生的声音,可能通过几个层以后,输入到 TTS 的模型这个产生出来的声音会变成也是“你好”的内容,但是完全听不出来是谁讲的,所以它真的学到去抹去讲述者的特征只保留内容的部分。
下面是两个真实的例子,如图 18.10 所示,上图有一个 5 层的 BiLSTM 模型,它将声音信息做为输入,输出是文字,这是一个语音识别的模型。给它一段女生的声音信息作为输入,同时再给它听另外一个男生讲不一样的内容。接下来我们把这些声音输入到网络里面,再把这个网络的嵌入用 TTS 的模型去还原回原来的声音。我们会发现第一层的声音信息有一点失真,但基本上跟原来是差不多的。但通过了 5 层的 BiLSTM 以后就听不出来是谁讲的,模型把两个人的声音都变成是一样的。另一个例子,输入的声音是有钢琴噪声的。网络是前面几层使用 CNN,后面几层使用 BiLSTM。信号通过第一层 CNN 以后还是钢琴的声音,但是通过了第一层 BiLSTM 以后,钢琴的声音就变得很小了,也就是钢琴的噪声被过滤了,前面的CNN 没有起到过滤噪声的工作。以上就是可解释机器学习中的局部解释。
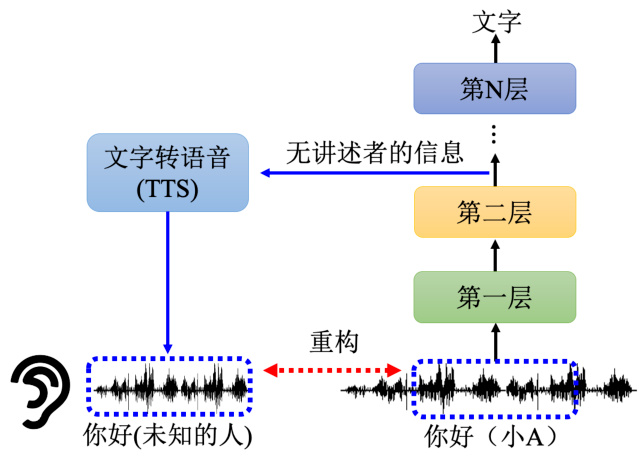
图 18.9 探针方法的在语音领域的案例
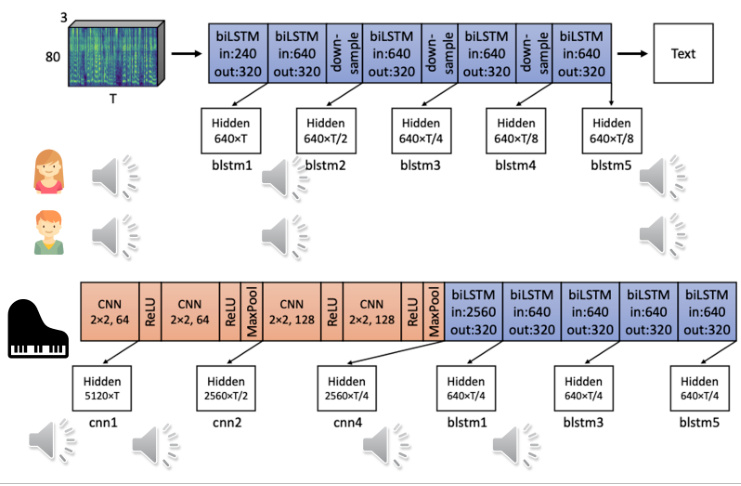
图 18.10 通过语音合成分析模型中的隐表征
18.5 可解释性机器学习中的全局解释
介绍完局部解释,接下来介绍全局的解释。局部的解释是给机器一张照片,让它告诉我们说看到这张图片,它为什么觉得里面有一只猫。与此不同的是,全局解释并不是针对特定某一张照片来进行分析,而是把我们训练好的模型拿出来,根据这个模型里面的参数去检查它的特性。也就是对这个网络而言,到底一只猫长什么样子,它心里想像的猫长什么样子。
比如假设我们训练好了一个卷积神经网络,模型如图 18.11 所示。假设有一张图片
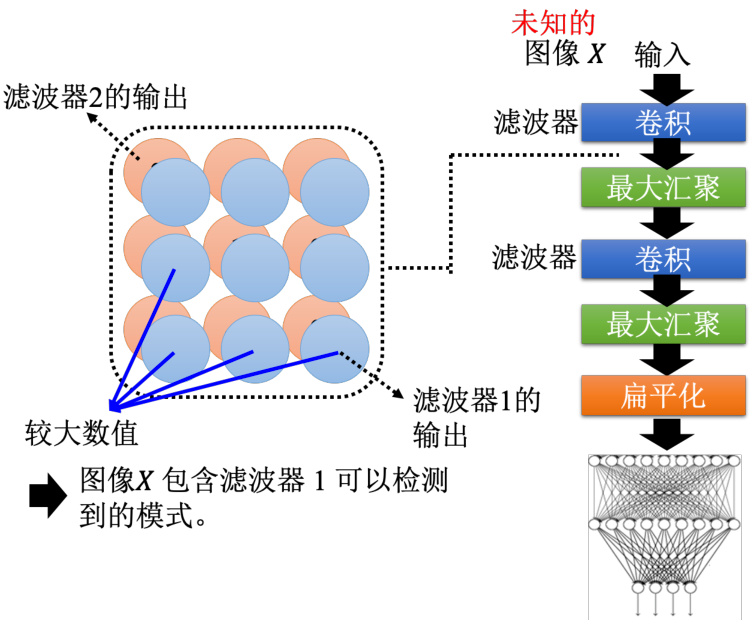
图 18.11 卷积神经网络中的滤波器可以检测的信息
下面我们使用 MNIST 手写数字识别的例子继续解释。我们训练好了一个卷积神经网络,它的结构如图 18.12 所示。接着继续使用 MNIST 数据集训练一个分类器,这个分类器的功能是给它一张图片它会判断其为
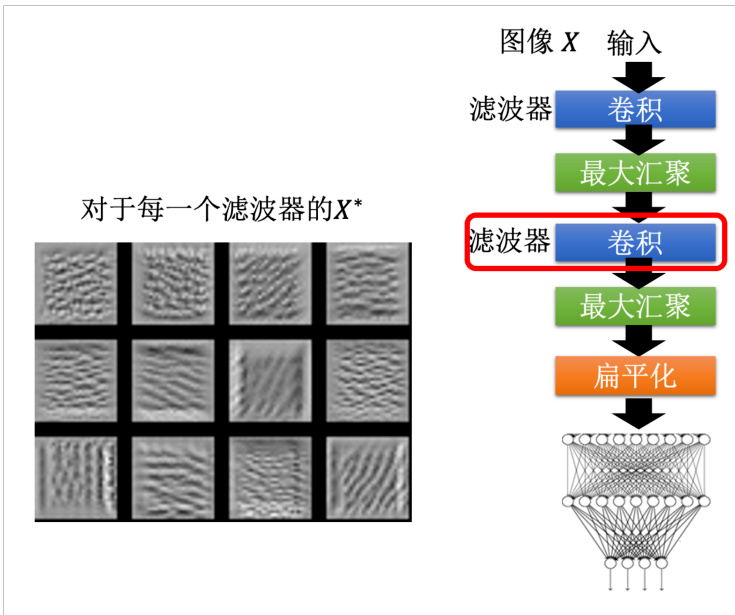
图 18.12 MNIST 数据集中的滤波器案例分析
从这些模式里面我们可以发现第二层的卷积确实是去挖掘一些基本的模式,比如说类似笔画的东西,比如横线、直线、斜线,而且每一个滤波器都有自己独有的想要挖掘的模式。因为我们现在是在做手写的数字识别,手写数字就是有一些笔画所构成的,所以卷积层里面的每一个滤波器的工作就是去侦测某一个笔画,这件事情是非常合理的。但是我们如果直接去看最终图像分类器输出的话,是完全分辨不出来不同的手写数字的,我们会观察到一些噪声信息。这里可以用我们之前介绍对抗攻击进行简单解释,在图像上面加上一些人眼根本看不到的噪声信息,就可以让机器看到各式各样的物体。这边也是一样的道理,对机器来说它不需要看到真的很像 0 的图片,它才说它看到数字 0。其实如果我们用这个可视化方法找一个图片,让图像的输出对应到某一个类别的输出越大越好,不一定有那么容易。
那如果我们希望看到的是比较像是人想像的数字应该要怎么办呢?方法是在解优化问题的时候,加上更多的限制。我们已经知道数字可能是长什么样子,所以要把这个限制加到这个优化的过程里。举例来说,我们现在不是要找一个
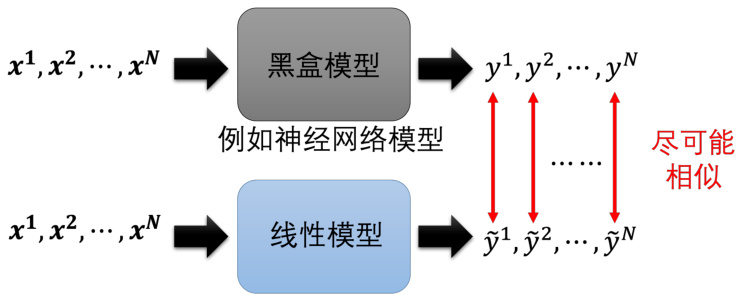
图 18.13 增加正则项前后的最终输出对比
如果我们希望使用全局解释性来看到非常清晰的图片的话,有一个方法就是训练一个图像生成器。我们可以用 GAN 或者 VAE 等等生成模型训练一个图像的生成器。图像的生成器的输入是一个从高斯分布里采样出来的低维度的向量叫做
我们再把
另外,解释性机器学习还是有比较强的主观性的,比如我们找出来的图片如果和自己主观想像的东西不一样,就会觉得这个解释的方法不好,就会硬是要使用一些技巧和方法去找出来和人想像的是一样的图片,我们才会说这个解释的方法是好的。这个过程或许和机器的理解相左。可解释性 AI 的技术往往就是有这个特性,我们其实没有那么在乎机器真正想的是什么。其实我们不知道机器真正想的是什么,只是希望有些方法解读出来的东西,让人看起来觉得很开心的就可以了。
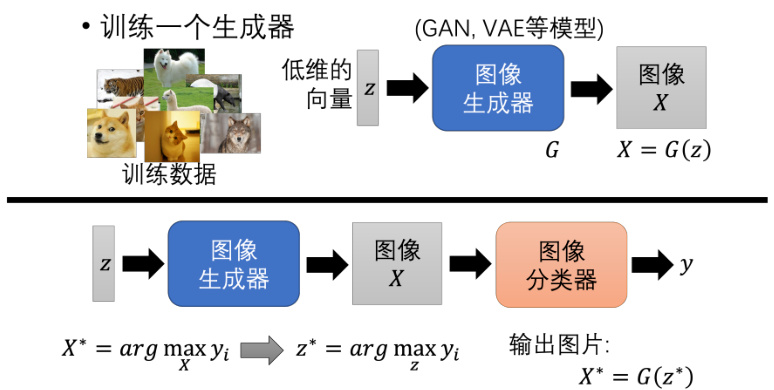
图 18.14 使用生成方法进行全局性解释
18.6 扩展与小结
那其实可解释性机器学习还有很多的技术,比如说我们可以用一些可解释性的模型来替代黑盒模型,比如说我们可以用线性模型来替代神经网络模型,如图 18.15 所示。也就是用一个比较简单的模型想办法去模仿复杂的模型的行为,如果简单的模型可以模仿复杂模型的行为,只需要去分析那个简单的模型,也许就可以知道复杂的模型在做什么。举例来说,一个深度的神经网络因为它是一个黑盒子,输入一些
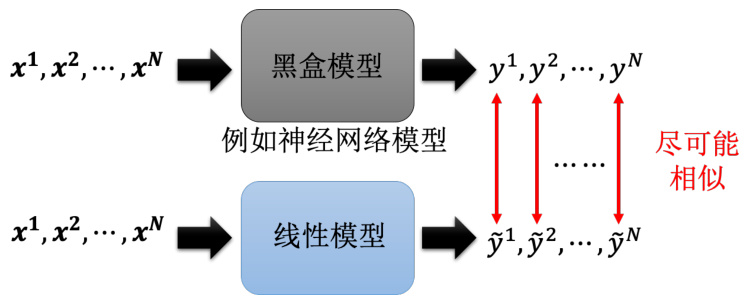
图 18.15 使用可解释模型模拟不可解释模型的行为
这里可能会有疑问,一个线性模型有办法去模仿一个黑盒的行为吗?我们在之前介绍过,有很多的问题是神经网络才做得到而线性模型做不到的。所以黑盒可以做到的事情线性模型不一定能做到。这里有一个特别知名的工作称为局部可解释的模型无关解释(Local Inter-pretable Model-agnostic Explanations,LIME)。这个方法也不能用线性模型去模仿黑盒全部的行为,但是它可以用线性模型去模仿黑盒在一个小的区域内的行为,这个区域内的行为是可以用线性模型去模仿的,所以它叫局部的可解释性。
以上就是关可解释性机器学习的介绍。这一章主要和大家介绍了可解释性机器学习的两个主流的技术,局部的解释和全局的解释。局部的解释主要是通过对于一个特定的样本,去找到一个和这个样本最相关的一些特征,把这些特征拿出来,去解释这个样本的分类结果。全局的解释主要是通过对于一个模型,去找到一些和这个模型最相关的一些特征,把这些特征拿出来,去解释这个模型的行为。